
Newest PyTorch Lightning release includes the final API with better data decoupling, shorter logging syntax and tons of bug fixes
We’re happy to release PyTorch Lightning 0.9.0 today, which contains many great new features, more bug fixes than any release we ever had, but most importantly it introduced our mostly final API changes!
Lightning is being adopted by top researchers and AI labs around the world, and we are working hard to make sure we provide a smooth experience and support for all the latest best practices. In this release, we are introducing two new major (and last) API changes:
LightningDataModules

Lightning is all about making your code more readable and structured. We decouple the model architecture from engineering, and we continue to do the same with data. To make sharing and reusing data splits and transforms across projects, we created LightningDataModules. A LightningDataModule is a shareable, reusable class that encapsulates all the steps needed for training:
- Download / tokenize / process.
- Clean and save to disk for reuse.
- Load inside Dataset in memory or just-in-time.
- Apply transforms (rotate, tokenize, etc…).
- Wrap inside a DataLoader.
LightningDataModules can be shared and used anywhere:
import pytorch_lightning as pl
from torch.utils.data import random_split, DataLoader
# Note - you must have torchvision installed for this example
from torchvision.datasets import MNIST
from torchvision import transforms
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = './'):
super().__init__()
self.data_dir = data_dir
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# self.dims is returned when you call dm.size()
# Setting default dims here because we know them.
# Could optionally be assigned dynamically in dm.setup()
self.dims = (1, 28, 28)
def prepare_data(self):
# download
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# Assign train/val datasets for use in dataloaders
if stage == 'fit' or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Optionally...
# self.dims = tuple(self.mnist_train[0][0].shape)
# Assign test dataset for use in dataloader(s)
if stage == 'test' or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
# Optionally...
# self.dims = tuple(self.mnist_test[0][0].shape)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=32)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=32)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=32)
model = LitClassifier()
trainer = Trainer()
mnist = MNISTDataModule()
trainer.fit(model, mnist)
In this video Nate Raw, DL research engineer at PyTorch Lightning, walks you step by step:
Step results
We added to Lightning two new results objects: TrainResult and EvalResult. They are fancy dictionary objects to hold outputs from train/eval/test steps. They are meant to control where and when to log and how synchronization is done across accelerators: Use TrainResult to auto log from training_step:
# without val/test loop you can add model checkpoint or early stop
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
result = pl.TrainResult(loss, early_stop_on=loss, checkpoint_on=loss)
result.log('train_loss', loss)
return result
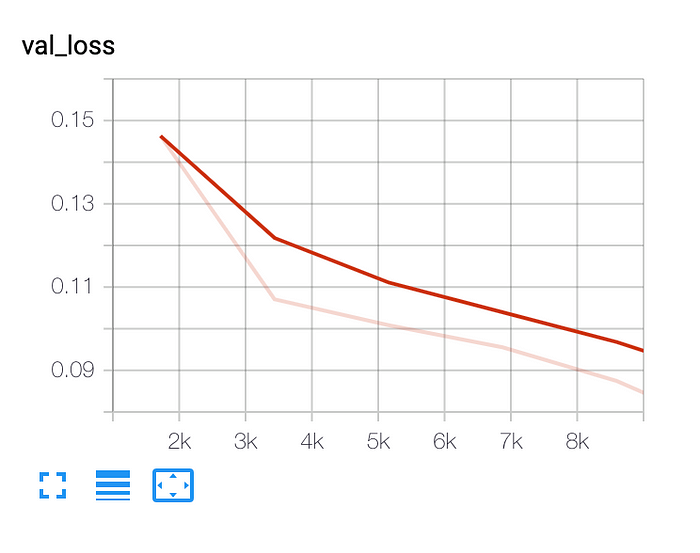
The ‘train_loss’ we added to TrainResult will generate automatic tensorboard logs (you can also use any of the other loggers we support):
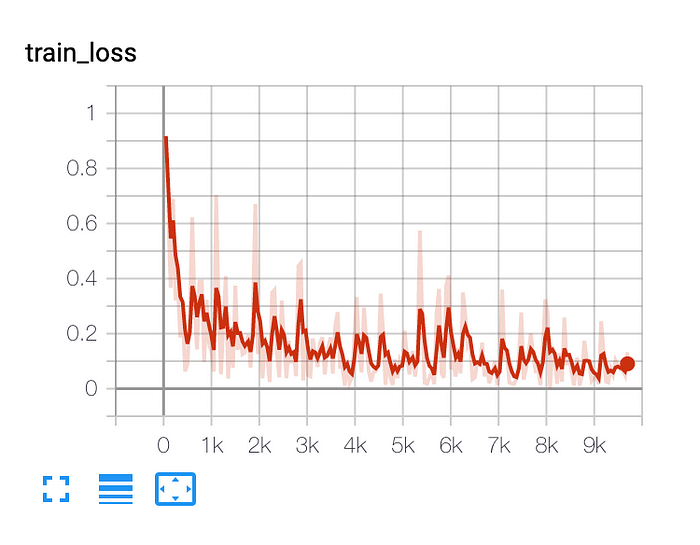
TrainResult default is to log every step of training.
Use EvalResult to auto log from validation_step or test_step:
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
result = EvalResult()
result.log('val_loss', loss)
return result
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
result = EvalResult()
result.log('test_loss', loss)
return result
EvalResult default is to log every epoch end.
Sync across devices
When training on multiple GPUs/CPUs/TPU cores, you can calculate the global mean of a logged metric as follows:
result.log('train_loss', loss, sync_dist=True)
For more logging options, check out our docs. A few other highlights of 0.9 include:
*PyTorch 1.6 support *Added saving test predictions on multiple GPUs *Added support to export a model to ONNX format *More sklearn metrics, SSIM, BLEU *Added SyncBN for DDP *Support for remote directories via gfile
Read the full release notes here.
We also upgraded our docs with some videos that illustrate core Lightning features in seconds! Check them out, and let us know what you’d like to see next!
We want to thank all our devoted contributors for their hard work, and to the community for all your help. We definitely wouldn’t get here without you. Try it out, share your projects on our #slack, and stay tuned for our next release- 1.0!