
Hi, I am Aleksei Shabanov — deep learning engineer, PhD student and one of the Catalyst’s contributors. Today I would like to tell you about a metric learning pipeline, which has been added in 20.08 release.
Note. Catalyst is a PyTorch framework for Deep Learning research and development. You get a training loop with metrics, model checkpointing, advanced logging and distributed training support without the boilerplate. Intro to Catalyst can be found here. Few words about metric learning
Roughly speaking, the goal of metric learning is to build a feature extractor with the following behaviour: it should map objects from the same class into the nearest points in the feature space and vice versa: distant points for different classes. These objects can be images, texts, sounds and so on. We will not discuss the theoretical side in detail, instead we will focus on the implementation. We designed our framework as a set of connected blocks with specified interfaces (python abstract classes). A user is able to add new logic via inheritance mechanism.
First, we should point out that training and validation stages of metric learning pipeline are completely different (in comparison with more common scenarios like classification when the only differences are augmentations and the source of DataLoader). So let’s take a look at these stages separately.
Training stage
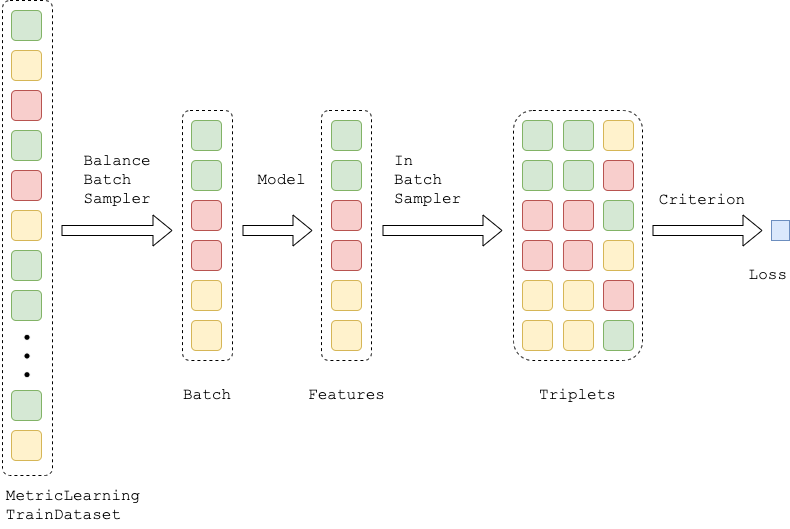 The idea of the training stage is as follows: we should sample pairs, triplets and quadruplets from the dataset and then calculate a pair-based, triplet-based or quadruplet-based loss. We’ve implemented a triplet-based scenario, but it can be easily adopted to other tasks.
The idea of the training stage is as follows: we should sample pairs, triplets and quadruplets from the dataset and then calculate a pair-based, triplet-based or quadruplet-based loss. We’ve implemented a triplet-based scenario, but it can be easily adopted to other tasks.
So let me introduce our design of the training stage which is based on two samplers: the first is to sample batches, the second is to sample triplets from these batches.
- The first one is implemented asBalanceBatchSampler which puts P instances for K classes into the batch (P, K ≥ 2). This behaviour guarantees that we can always form the triplets inside the batch and overcome classes’ imbalance. Note that BalanceBatchSampler should be provided with information about the classes of all the items in the dataset. For this purpose the dataset should be a child of MetricLearningTrainDataset. (Note, that BalanceBatchSampler сan be useful for a classic scenario as well, such as training a classifier.)
- The second one is represented by an abstract class InBatchTripletsSampler and its ready-to-use children: AllTripletsSampler , HardTripletsSampler and HardClusterSampler. After triplets have been formed, they are used as an input of TripletMarginLoss from PyTorch. The in-batch sampling and loss calculation are united in TripletMarginLossWithSampler.
dataset_train = datasets.MnistMLDataset(root=dataset_root, train=True, download=True, transform=transforms)
sampler = data.BalanceBatchSampler(labels=dataset_train.get_labels(), p=10, k=10)
train_loader = DataLoader(dataset=dataset_train, sampler=sampler, batch_size=sampler.batch_size)
sampler_inbatch = data.HardTripletsSampler(norm_required=False)
criterion = nn.TripletMarginLossWithSampler(margin=0.5, sampler_inbatch=sampler_inbatch)
Note. Intuitively, it might seem that it is easier to implement Dataset that will return triplets. But this approach has several significant drawbacks. Firstly, it is extremely ineffective, this is due to that fact that the hardest part of computing is feature extracting. If we have already extracted features from the objects, we would like to use as many triplets as possible, because triplets selecting is a lightweight procedure. But if the triplets are selected in advance, we will lose a large number of potential triplets. Secondly, such a mode of triplets selection as ‘hard’ cannot be performed if the search is carried out within the entire dataset. At the same time, with InBatchSampler you can search for the hard samples in a reasonable time.
Validation stage
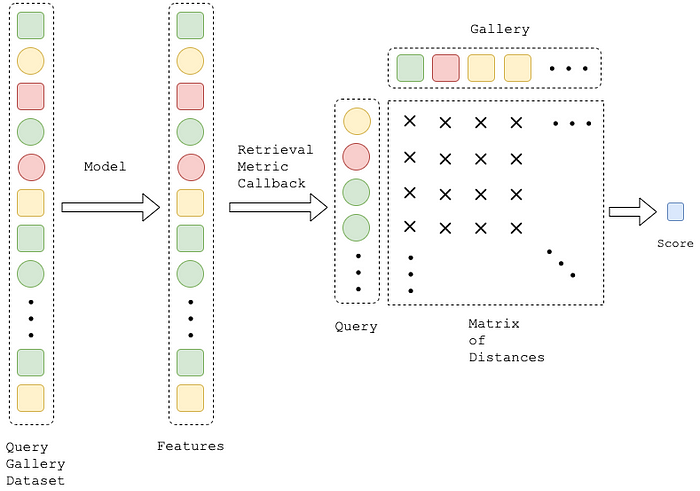 For model evaluation query/gallery protocol is usually used. It means that we should split a validation dataset to query and gallery parts, calculate a distance matrix based on extracted features and apply one of the retrieval metrics. The idea is that the metric will be better if the gallery elements closest to the query have the same class. If you work with academic retrieval datasets, then along with them is attached information on the exact query/gallery split. If you work with your custom dataset the split should be done based on domain knowledge. Note, that MNIST dataset is not a retrieval dataset, that is why we just simply pick 20% of it as a query.
For model evaluation query/gallery protocol is usually used. It means that we should split a validation dataset to query and gallery parts, calculate a distance matrix based on extracted features and apply one of the retrieval metrics. The idea is that the metric will be better if the gallery elements closest to the query have the same class. If you work with academic retrieval datasets, then along with them is attached information on the exact query/gallery split. If you work with your custom dataset the split should be done based on domain knowledge. Note, that MNIST dataset is not a retrieval dataset, that is why we just simply pick 20% of it as a query.
To provide information about query/gallery split of your dataset it should be implemented as a child of QueryGalleryDataset, you can use MnistQGDatset as an example. With reference to the metric, it can be implemented as a new callback or you can pick ready-to-useCMCScoreCallback. The last one accumulates features of all the samples from the validation loader, then builds a matrix of distances between queries and galleries and finally calculates Cumulative Matching Characteristic (CMC).
dataset_val = datasets.MnistQGDataset(root=dataset_root, transform=transforms, gallery_fraq=0.2)
val_loader = DataLoader(dataset=dataset_val, batch_size=1024)
metric_callback = dl.CMCScoreCallback(topk_args=[1]), loaders="valid")
The whole pipeline
Before putting things together via SupervisedRunner, let us focus on two facts:
- Since the designs of training and validation stages are different, we cannot call criterion on val_loader and also apply CMCScoreCallback on the train_loader. The required behavior is provided by ControlFlowCallback.
- We define training epoch as a process by which we go through all the classes from the training dataset (instead of all the samples in the classical scenario). It makes these training epoch very quick. At the same time, validation epoch includes all the samples in the query/gallery dataset. As a result we should run the validation stage much less often than the training stage. PeriodicLoaderCallback is used for this.
To sum it up, the complete pipeline is presented below. It can also be found in Catalyst’s Readme as a minimal example called CV — MNIST with Metric Learning.
from torch.optim import Adam
from torch.utils.data import DataLoader
from catalyst import data, dl, utils
from catalyst.contrib import datasets, models, nn
import catalyst.data.cv.transforms.torch as t
# 1. train and valid datasets
dataset_root = "."
transforms = t.Compose([t.ToTensor(), t.Normalize((0.1307,), (0.3081,))])
dataset_train = datasets.MnistMLDataset(root=dataset_root, train=True, download=True, transform=transforms)
sampler = data.BalanceBatchSampler(labels=dataset_train.get_labels(), p=10, k=10)
train_loader = DataLoader(dataset=dataset_train, sampler=sampler, batch_size=sampler.batch_size)
dataset_val = datasets.MnistQGDataset(root=dataset_root, transform=transforms, gallery_fraq=0.2)
val_loader = DataLoader(dataset=dataset_val, batch_size=1024)
# 2. model and optimizer
model = models.SimpleConv(features_dim=16)
optimizer = Adam(model.parameters(), lr=0.001)
# 3. criterion with triplets sampling
sampler_inbatch = data.HardTripletsSampler(norm_required=False)
criterion = nn.TripletMarginLossWithSampler(margin=0.5, sampler_inbatch=sampler_inbatch)
# 4. training with catalyst Runner
callbacks = [
dl.ControlFlowCallback(dl.CriterionCallback(), loaders="train"),
dl.ControlFlowCallback(dl.CMCScoreCallback(topk_args=[1]), loaders="valid"),
dl.PeriodicLoaderCallback(valid=300),
]
runner = dl.SupervisedRunner(device=utils.get_device())
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
callbacks=callbacks,
loaders={"train": train_loader, "valid": val_loader},
minimize_metric=False,
verbose=True,
valid_loader="valid",
num_epochs=600,
main_metric="cmc01",
)
view raw
I hope this tutorial was useful to you. More details are available in the documentation and minimal examples. Do not hesitate to adopt this code to your task and ask any questions in our slack community I also especially thank Nikita, Julia, and Sergey for their help and advices during metric learning feature-release. See you in the next posts!